CloudNet@팀의 EKS 스터디 AEWS 2기에 작성된 자료를 토대로 작성합니다.
in-place Cluster Upgrade : 1.25 -> 1.26
업그레이드 단계
- 클러스터 제어 평면 업그레이드
- Kubernetes 애드온 및 사용자 정의 컨트롤러를 업데이트하세요.
- 클러스터의 노드를 업그레이드하세요
필요한 경우 사용되지 않는 API를 제거하고 Kubernetes 매니페스트를 업데이트하여 적절한 리소스를 수정한 후, 위의 순서대로 클러스터를 업그레이드할 수 있습니다. 이러한 단계는 테스트 환경에서 완료하는 것이 가장 좋으므로 프로덕션 클러스터에서 업그레이드 작업을 시작하기 전에 클러스터 구성과 애플리케이션 매니페스트의 문제를 발견할 수 있습니다.
방법 1 : eksctl 아래 실행하지 않음!
이 명령에서 대상 버전을 지정할 수 있지만 --version에 허용되는 값은 클러스터의 현재 버전 또는 한 버전 더 높은 버전입니다. 현재 두 개 이상의 Kubernetes 버전 업그레이드는 지원되지 않습니다.
eksctl upgrade cluster --name $EKS_CLUSTER_NAME --approve방법 2 : AWS 관리 콘솔 : skip , 아래 실행하지 않음!
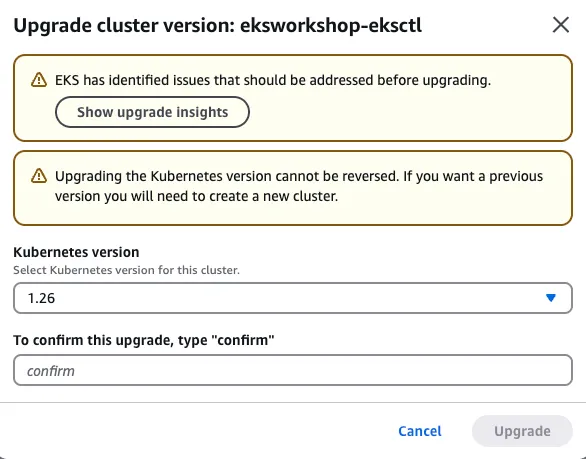
방법 3 : aws cli 아래 실행하지 않음!
클러스터에 관리되는 노드 그룹이 연결되어 있는 경우, 클러스터를 새로운 Kubernetes 버전으로 업데이트하려면 모든 노드 그룹의 Kubernetes 버전이 클러스터의 Kubernetes 버전과 일치해야 합니다.
aws eks update-cluster-version --region ${AWS_REGION} --name $EKS_CLUSTER_NAME --kubernetes-version 1.26
{
"update": {
"id": "b5f0ba18-9a87-4450-b5a0-825e6e84496f",
"status": "InProgress",
"type": "VersionUpdate",
"params": [
{
"type": "Version",
"value": "1.26"
},
{
"type": "PlatformVersion",
"value": "eks.1"
}
],
[...]
"errors": []
}
}
# 다음 명령으로 클러스터 업데이트 상태를 모니터링할 수 있습니다. 이전 명령에서 반환한 클러스터 이름과 업데이트 ID를 사용합니다.
# Successful 상태가 표시되면 업데이트가 완료된 것입니다.
aws eks describe-update --region ${AWS_REGION} --name $EKS_CLUSTER_NAME --update-id b5f0ba18-9a87-4450-b5a0-825e6e84496f1. [제어평면] Upgrading EKS Control-plane
방법 4 : Terraform , 해당 방법으로 실제 업그레이드 실행!
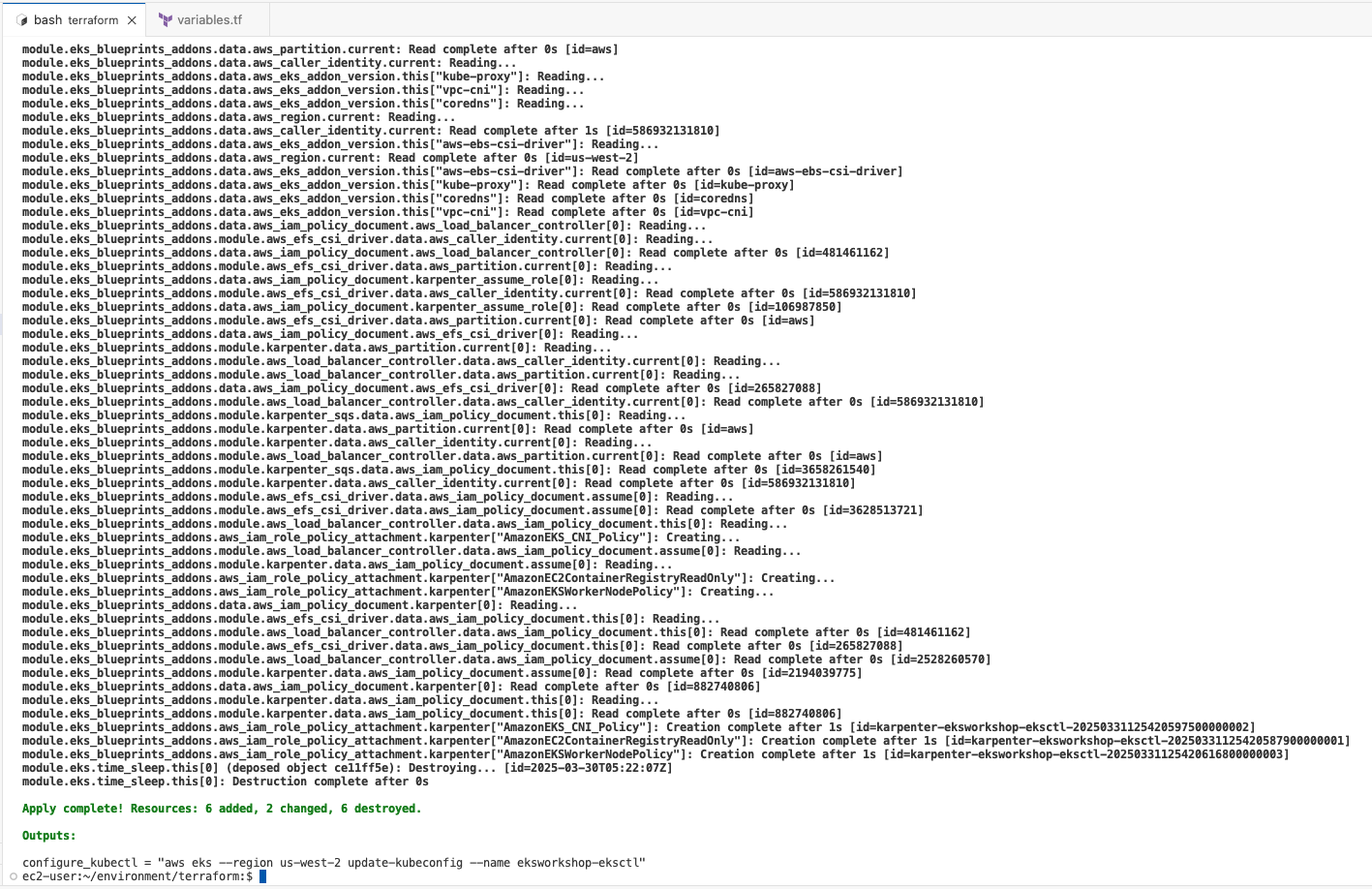
- 이 랩에서는 terraform을 사용하여 클러스터를 업그레이드합니다. EKS 클러스터는 이미 terraform을 통해 이 랩에 프로비저닝되었습니다. terraform init, plan 및 apply를 수행하여 리소스 상태를 새로 고칩니다.
#
cd ~/environment/terraform
terraform state list- 모니터링을 위한 작업 추가
# 현재 버전 확인 : 파일로 저장해두기
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c > 1.25.txt
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon-k8s-cni:v1.19.3-eksbuild.1
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon/aws-network-policy-agent:v1.2.0-eksbuild.1
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/aws-ebs-csi-driver:v1.41.0
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/coredns:v1.8.7-eksbuild.10
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-attacher:v4.8.1-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-node-driver-registrar:v2.13.0-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-provisioner:v5.2.0-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-resizer:v1.13.2-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-snapshotter:v8.2.1-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/kube-proxy:v1.25.16-minimal-eksbuild.8
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/livenessprobe:v2.14.0-eks-1-32-7
8 amazon/aws-efs-csi-driver:v1.7.6
1 amazon/dynamodb-local:1.13.1
1 ghcr.io/dexidp/dex:v2.38.0
1 hjacobs/kube-ops-view:20.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-assets:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-cart:0.7.0
1 public.ecr.aws/aws-containers/retail-store-sample-catalog:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-checkout:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-orders:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-ui:0.4.0
1 public.ecr.aws/bitnami/rabbitmq:3.11.1-debian-11-r0
2 public.ecr.aws/docker/library/mysql:8.0
1 public.ecr.aws/docker/library/redis:6.0-alpine
1 public.ecr.aws/docker/library/redis:7.0.15-alpine
2 public.ecr.aws/eks-distro/kubernetes-csi/external-provisioner:v3.6.3-eks-1-29-2
8 public.ecr.aws/eks-distro/kubernetes-csi/livenessprobe:v2.11.0-eks-1-29-2
6 public.ecr.aws/eks-distro/kubernetes-csi/node-driver-registrar:v2.9.3-eks-1-29-2
2 public.ecr.aws/eks/aws-load-balancer-controller:v2.7.1
2 public.ecr.aws/karpenter/controller:0.37.0@sha256:157f478f5db1fe999f5e2d27badcc742bf51cc470508b3cebe78224d0947674f
5 quay.io/argoproj/argocd:v2.10.0
1 registry.k8s.io/metrics-server/metrics-server:v0.7.0
# IDE-Server 혹은 자신의 PC에서 반복 접속 해두자!
export UI_WEB=$(kubectl get svc -n ui ui-nlb -o jsonpath='{.status.loadBalancer.ingress[0].hostname}'/actuator/health/liveness)
curl -s $UI_WEB ; echo
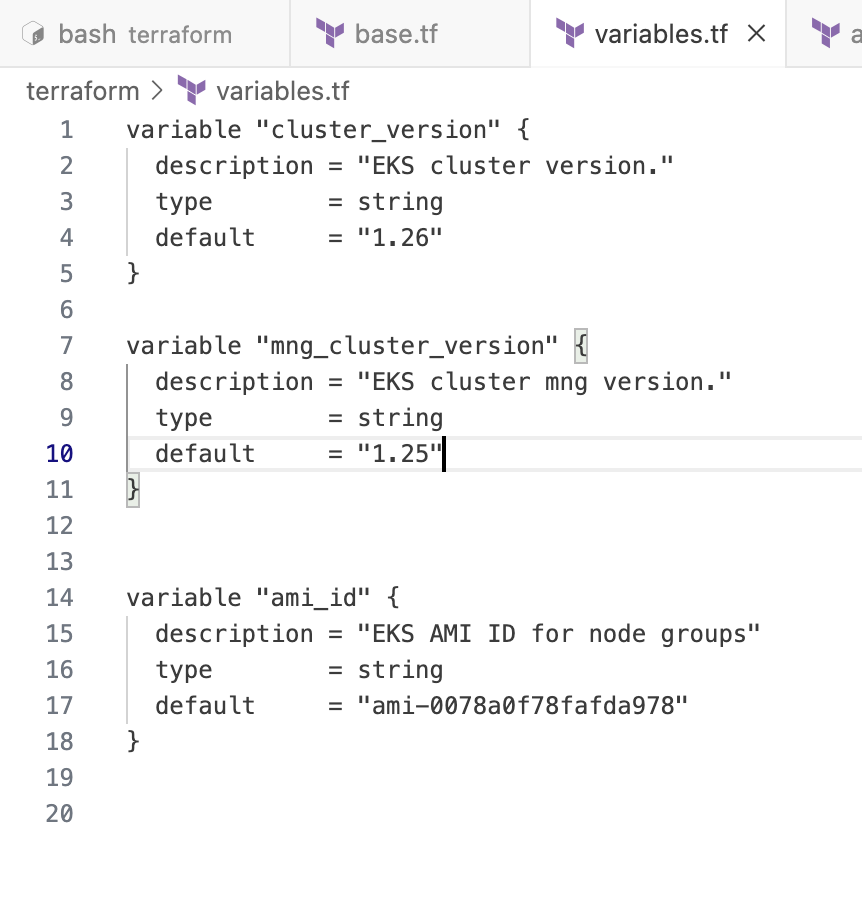
{"status":"UP"}eks 모듈에서 eks 클러스터 구성을 볼 수 있습니다 base.tf. cluster_version의 값은 variable.tf의 변수 cluster_version에 정의되어 있습니다. 현재는 아래처럼 설정되어 있습니다

variable.tf의 cluster_version 변수를 1.26 로 변경하고 terraform plan을 실행해 봅시다.
# 기본 정보
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
"version": "1.25",
"endpoint": "https://xxxx.gr7.us-west-2.eks.amazonaws.com",
"issuer": "https://oidc.eks.us-west-2.amazonaws.com/id/xxxx"
"platformVersion": "eks.44",
# Plan을 적용하면 Terraform이 어떤 변경을 하는지 볼 수 있습니다.
terraform plan
terraform plan -no-color > plan-output.txt # IDE에서 열어볼것
...- 테라폼 apply를 통한 업그레이드
# 기본 정보
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
# 클러스터 버전을 변경하면 테라폼 계획에 표시된 것처럼, 관리 노드 그룹에 대한 특정 버전이나 AMI가 테라폼 파일에 정의되지 않은 경우,
# eks 클러스터 제어 평면과 관리 노드 그룹 및 애드온과 같은 관련 리소스를 업데이트하게 됩니다.
# 이 계획을 적용하여 제어 평면 버전을 업데이트해 보겠습니다.
terraform apply -auto-approve # 10분 소요
# eks control plane 1.26 업글 확인
aws eks describe-cluster --name $EKS_CLUSTER_NAME | jq
...
"version": "1.26",
# endpoint, issuer, platformVersion 동일 => IRSA 를 사용하는 4개의 App 동작에 문제 없음!
aws eks describe-cluster --name $EKS_CLUSTER_NAME | egrep 'version|endpoint"|issuer|platformVersion'
# 파드 컨테이너 이미지 버전 모두 동일
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c > 1.26.txt
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
diff 1.26.txt 1.25.txt # 동일함
# 파드 AGE 정보 확인 : 재생성된 파드 없음!
kubectl get pod -A
...

- Deprecated API란?
Deprecated API"는 더 이상 권장되지 않는 API를 의미합니다. 즉, 해당 API는 여전히 사용할 수는 있지만, 미래에 제거될 예정이기 때문에 더 이상 사용하지 않는 것이 좋다는 뜻이에요.
왜 API가 Deprecated 되는가?
- 보안상의 이유 – 더 안전한 방식이 도입되었을 때
- 성능 개선 – 새로운 API가 성능이 더 좋을 때
- 유지보수 편의성 – 코드 구조를 단순하게 만들기 위해
- 더 나은 기능 제공 – 더 많은 기능이나 더 직관적인 방식이 나왔을 때
Kubent 소개
k8s 버전 업그레이드 작업 전 deprecated /removed API를 확인 해야 합니다.
- kubent는 kubectl의 현재 컨텍스트를 클러스터를 가리키도록 설정 한 후 사용합니다.
-> kubent는 기본 위치에 있는 kube .config 파일을 찾아 사용합니다 (또는 -k 옵션을 사용해 사용자 지정 위치를 지정할 수 있습니다). - kubent는 클러스터에서 리소스를 수집하고, 발견된 문제들을 보고합니다.
주의: Helm 관련 수집기를 사용하려면 클러스터에서 Secrets를 읽을 수 있는 충분한 권한이 필요합니다.
git clone https://github.com/doitintl/kube-no-trouble.git
cd kube-no-trouble/
cd scripts/
sh install.sh
kubent
ec2-user:~/environment/kube-no-trouble:$ kubent
11:28PM INF >>> Kube No Trouble `kubent` <<<
11:28PM INF version 0.7.3 (git sha 57480c07b3f91238f12a35d0ec88d9368aae99aa)
11:28PM INF Initializing collectors and retrieving data
11:28PM INF Target K8s version is 1.26.15-eks-bc803b4
11:29PM INF Retrieved 93 resources from collector name=Cluster
11:29PM INF Retrieved 97 resources from collector name="Helm v3"
11:29PM INF Loaded ruleset name=custom.rego.tmpl
11:29PM INF Loaded ruleset name=deprecated-1-16.rego
11:29PM INF Loaded ruleset name=deprecated-1-22.rego
11:29PM INF Loaded ruleset name=deprecated-1-25.rego
11:29PM INF Loaded ruleset name=deprecated-1-26.rego
11:29PM INF Loaded ruleset name=deprecated-1-27.rego
11:29PM INF Loaded ruleset name=deprecated-1-29.rego
11:29PM INF Loaded ruleset name=deprecated-1-32.rego
11:29PM INF Loaded ruleset name=deprecated-future.rego
__________________________________________________________________________________________
>>> Deprecated APIs removed in 1.26 <<<
------------------------------------------------------------------------------------------
KIND NAMESPACE NAME API_VERSION REPLACE_WITH (SINCE)
HorizontalPodAutoscaler ui ui autoscaling/v2beta2 autoscaling/v2 (1.23.0)
ec2-user:~/environment/kube-no-trouble:$- 검출된 HPA의 yaml을 확인
ec2-user:~/environment/kube-no-trouble:$ kubectl get hpa -n ui ui -o yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"autoscaling/v2beta2","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"labels":{"argocd.argoproj.io/instance":"ui"},"name":"ui","namespace":"ui"},"spec":{"maxReplicas":4,"minReplicas":1,"scaleTargetRef":{"apiVersion":"apps/v1","kind":"Deployment","name":"ui"},"targetCPUUtilizationPercentage":80}}
creationTimestamp: "2025-03-30T05:32:45Z"
labels:
argocd.argoproj.io/instance: ui
name: ui
namespace: ui
resourceVersion: "1055212"
uid: a2c3cadf-db3c-4d1f-ae7f-0389bdcd4e0f
spec:
maxReplicas: 4
metrics:
- resource:
name: cpu
target:
averageUtilization: 80
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ui
status:
conditions:
- lastTransitionTime: "2025-03-30T05:33:00Z"
message: recommended size matches current size
reason: ReadyForNewScale
status: "True"
type: AbleToScale
- lastTransitionTime: "2025-03-30T05:33:30Z"
message: the HPA was able to successfully calculate a replica count from cpu resource
utilization (percentage of request)
reason: ValidMetricFound
status: "True"
type: ScalingActive
- lastTransitionTime: "2025-03-31T23:11:05Z"
message: the desired replica count is less than the minimum replica count
reason: TooFewReplicas
status: "True"
type: ScalingLimited
currentMetrics:
- resource:
current:
averageUtilization: 0
averageValue: 1m
name: cpu
type: Resource
currentReplicas: 1
desiredReplicas: 1
lastScaleTime: "2025-03-30T05:38:46Z"- annotation( last-applied) 에 확인 해보면 v2beta2 버전으로 이전 버전이 기록된 메타데이터가 있음
kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"autoscaling/v2beta2","kind":"HorizontalPodAutoscaler","metadata":{"annotations":{},"labels":{"argocd.argoproj.io/instance":"ui"},"name":"ui","namespace":"ui"},"spec":{"maxReplicas":4,"minReplicas":1,"scaleTargetRef":{"apiVersion":"apps/v1","kind":"Deployment","name":"ui"},"targetCPUUtilizationPercentage":80}}- 해당 hpa를 백업해놓고 last-applied-configuration 부분 삭제하여 다시 배포
ec2-user:~/environment/kube-no-trouble:$ kubectl get hpa -n ui ui -o yaml > hpa_ui.yaml
ec2-user:~/environment/kube-no-trouble:$ ls
Dockerfile LICENSE Makefile README.md cliff.toml cmd docs fixtures go.mod go.sum hpa_ui.yaml pkg scripts test
ec2-user:~/environment/kube-no-trouble:$
ec2-user:~/environment/kube-no-trouble:$ kubectl delete hpa -n ui ui
horizontalpodautoscaler.autoscaling "ui" deleted
ec2-user:~/environment/kube-no-trouble:$ cp hpa_ui.yaml hpa_ui_fix.yaml
ec2-user:~/environment/kube-no-trouble:$ vim hpa_ui_fix.yaml
ec2-user:~/environment/kube-no-trouble:$
ec2-user:~/environment/kube-no-trouble:$
ec2-user:~/environment/kube-no-trouble:$ kubectl apply -f hpa_ui_fix.yaml- 다시 kubent 실행 ( 검출안됨 확인)
ec2-user:~/environment/kube-no-trouble:$ kubent
11:38PM INF >>> Kube No Trouble `kubent` <<<
11:38PM INF version 0.7.3 (git sha 57480c07b3f91238f12a35d0ec88d9368aae99aa)
11:38PM INF Initializing collectors and retrieving data
11:38PM INF Target K8s version is 1.26.15-eks-bc803b4
11:39PM INF Retrieved 93 resources from collector name=Cluster
11:39PM INF Retrieved 97 resources from collector name="Helm v3"
11:39PM INF Loaded ruleset name=custom.rego.tmpl
11:39PM INF Loaded ruleset name=deprecated-1-16.rego
11:39PM INF Loaded ruleset name=deprecated-1-22.rego
11:39PM INF Loaded ruleset name=deprecated-1-25.rego
11:39PM INF Loaded ruleset name=deprecated-1-26.rego
11:39PM INF Loaded ruleset name=deprecated-1-27.rego
11:39PM INF Loaded ruleset name=deprecated-1-29.rego
11:39PM INF Loaded ruleset name=deprecated-1-32.rego
11:39PM INF Loaded ruleset name=deprecated-future.rego
ec2-user:~/environment/kube-no-trouble:$2. [애드온] Upgrading EKS Addons*
- EKS 업그레이드의 일부로 클러스터에 설치된 애드온을 업그레이드해야 합니다.
- 애드온은 K8s 애플리케이션에 지원 운영 기능을 제공하는 소프트웨어로, 네트워킹, 컴퓨팅 및 스토리지를 위해 클러스터가 기본 AWS 리소스와 상호 작용할 수 있도록 하는 관찰 에이전트 또는 Kubernetes 드라이버와 같은 소프트웨어가 포함됩니다.
- 애드온 소프트웨어는 일반적으로 Kubernetes 커뮤니티, AWS와 같은 클라우드 공급자 또는 타사 공급업체에서 빌드하고 유지 관리합니다.
Upgrading EKS addons - 실습
- eksctl을 사용하여 EKS 1.25의 기존 애드온을 보려면 : 가능한 업그레이드 버전 정보 확인!
ec2-user:~/environment/kube-no-trouble:$ eksctl get addon --cluster $CLUSTER_NAME
2025-04-01 00:09:47 [ℹ] Kubernetes version "1.26" in use by cluster "eksworkshop-eksctl"
2025-04-01 00:09:47 [ℹ] getting all addons
2025-04-01 00:09:48 [ℹ] to see issues for an addon run `eksctl get addon --name <addon-name> --cluster <cluster-name>`
NAME VERSION STATUS ISSUES IAMROLE UPDATE AVAILABLE CONFIGURATION VALUES
aws-ebs-csi-driver v1.41.0-eksbuild.1 ACTIVE 0 arn:aws:iam::586932131810:role/eksworkshop-eksctl-ebs-csi-driver-2025033005213840970000001d
coredns v1.8.7-eksbuild.10 ACTIVE 0 v1.9.3-eksbuild.22,v1.9.3-eksbuild.21,v1.9.3-eksbuild.19,v1.9.3-eksbuild.17,v1.9.3-eksbuild.15,v1.9.3-eksbuild.11,v1.9.3-eksbuild.10,v1.9.3-eksbuild.9,v1.9.3-eksbuild.7,v1.9.3-eksbuild.6,v1.9.3-eksbuild.5,v1.9.3-eksbuild.3,v1.9.3-eksbuild.2
kube-proxy v1.25.16-eksbuild.8 ACTIVE 0 v1.26.15-eksbuild.24,v1.26.15-eksbuild.19,v1.26.15-eksbuild.18,v1.26.15-eksbuild.14,v1.26.15-eksbuild.10,v1.26.15-eksbuild.5,v1.26.15-eksbuild.2,v1.26.13-eksbuild.2,v1.26.11-eksbuild.4,v1.26.11-eksbuild.1,v1.26.9-eksbuild.2,v1.26.7-eksbuild.2,v1.26.6-eksbuild.2,v1.26.6-eksbuild.1,v1.26.4-eksbuild.1,v1.26.2-eksbuild.1
vpc-cni v1.19.3-eksbuild.1 ACTIVE 0- terraform을 사용하여 CoreDNS , kube-proxy 및 VPC CNI 의 업그레이드를 살펴보겠습니다. 이를 위해 파일에서 CoreDNS, kube-proxy 및 VPC CNI의 버전을 업데이트하기만 하면 됩니다
eks_addons = {
coredns = {
addon_version = "v1.8.7-eksbuild.10"
}
kube-proxy = {
addon_version = "v1.25.16-eksbuild.8"
}
vpc-cni = {
most_recent = true
}
aws-ebs-csi-driver = {
service_account_role_arn = module.ebs_csi_driver_irsa.iam_role_arn
}
}- Amazon EKS는 AWS Managed Addons에 대한 주어진 K8s 버전에 대한 호환되는 애드온 버전을 나열하는 API를 제공합니다. 다음 명령을 사용하여 1.26 호환되는 coredns애드온 버전을 찾을 수 있습니다.
#
kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon-k8s-cni:v1.19.3-eksbuild.1
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/aws-ebs-csi-driver:v1.41.0
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/coredns:v1.8.7-eksbuild.10
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-provisioner:v5.2.0-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/kube-proxy:v1.25.16-minimal-eksbuild.8
8 amazon/aws-efs-csi-driver:v1.7.6
2 public.ecr.aws/eks/aws-load-balancer-controller:v2.7.1
#
aws eks describe-addon-versions --addon-name coredns --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
------------------------------------------
| DescribeAddonVersions |
+-----------------+----------------------+
| DefaultVersion | Version |
+-----------------+----------------------+
| False | v1.9.3-eksbuild.22 |
| False | v1.9.3-eksbuild.21 |
| False | v1.9.3-eksbuild.19 |
| False | v1.9.3-eksbuild.17 |
| False | v1.9.3-eksbuild.15 |
| False | v1.9.3-eksbuild.11 |
| False | v1.9.3-eksbuild.10 |
| False | v1.9.3-eksbuild.9 |
| True | v1.9.3-eksbuild.7 |
| False | v1.9.3-eksbuild.6 |
+-----------------+----------------------+
#
aws eks describe-addon-versions --addon-name kube-proxy --kubernetes-version 1.26 --output table \
--query "addons[].addonVersions[:10].{Version:addonVersion,DefaultVersion:compatibilities[0].defaultVersion}"
--------------------------------------------
| DescribeAddonVersions |
+-----------------+------------------------+
| DefaultVersion | Version |
+-----------------+------------------------+
| False | v1.26.15-eksbuild.24 |
| False | v1.26.15-eksbuild.19 |
| False | v1.26.15-eksbuild.18 |
| False | v1.26.15-eksbuild.14 |
| False | v1.26.15-eksbuild.10 |
| False | v1.26.15-eksbuild.5 |
| False | v1.26.15-eksbuild.2 |
| False | v1.26.13-eksbuild.2 |
| False | v1.26.11-eksbuild.4 |
| False | v1.26.11-eksbuild.1 |
+-----------------+------------------------+
- 변경 사항을 저장 하고 적용합니다.
# 반복 접속 : 아래 coredns, kube-proxy addon 업그레이드 시 ui 무중단 통신 확인!
aws eks update-kubeconfig --name eksworkshop-eksctl # 자신의 집 PC일 경우
kubectl get pod -n kube-system -l k8s-app=kube-dns
kubectl get pod -n kube-system -l k8s-app=kube-proxy
kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'
while true; do curl -s $UI_WEB ; date; kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'; echo ; sleep 2; done
#
cd ~/environment/terraform/
terraform plan -no-color | tee addon.txt
...
# module.eks_blueprints_addons.aws_eks_addon.this["coredns"] will be updated in-place
~ resource "aws_eks_addon" "this" {
~ addon_version = "v1.8.7-eksbuild.10" -> "v1.9.3-eksbuild.22"
id = "eksworkshop-eksctl:coredns"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
# (11 unchanged attributes hidden)
# (1 unchanged block hidden)
}
# module.eks_blueprints_addons.aws_eks_addon.this["kube-proxy"] will be updated in-place
~ resource "aws_eks_addon" "this" {
~ addon_version = "v1.25.16-eksbuild.8" -> "v1.26.15-eksbuild.24"
id = "eksworkshop-eksctl:kube-proxy"
tags = {
"Blueprint" = "eksworkshop-eksctl"
"GithubRepo" = "github.com/aws-ia/terraform-aws-eks-blueprints"
}
...
# 1분 정도 이내로 롤링 업데이트 완료!
terraform apply -auto-approve
#
kubectl get pod -n kube-system -l 'k8s-app in (kube-dns, kube-proxy)'
NAME READY STATUS RESTARTS AGE
coredns-58cc4d964b-7867s 1/1 Running 0 71s
coredns-58cc4d964b-qb8zc 1/1 Running 0 71s
kube-proxy-2f6nv 1/1 Running 0 61s
kube-proxy-7n8xj 1/1 Running 0 67s
kube-proxy-7p4p2 1/1 Running 0 70s
kube-proxy-g2vvp 1/1 Running 0 54s
kube-proxy-ks4xp 1/1 Running 0 64s
kube-proxy-kxvh5 1/1 Running 0 57s
#
ec2-user:~/environment/terraform:$ kubectl get pods --all-namespaces -o jsonpath="{.items[*].spec.containers[*].image}" | tr -s '[[:space:]]' '\n' | sort | uniq -c
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon-k8s-cni:v1.19.3-eksbuild.1
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/amazon/aws-network-policy-agent:v1.2.0-eksbuild.1
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/aws-ebs-csi-driver:v1.41.0
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/coredns:v1.9.3-eksbuild.22
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-attacher:v4.8.1-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-node-driver-registrar:v2.13.0-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-provisioner:v5.2.0-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-resizer:v1.13.2-eks-1-32-7
2 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/csi-snapshotter:v8.2.1-eks-1-32-7
6 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/kube-proxy:v1.26.15-minimal-eksbuild.24
8 602401143452.dkr.ecr.us-west-2.amazonaws.com/eks/livenessprobe:v2.14.0-eks-1-32-7
8 amazon/aws-efs-csi-driver:v1.7.6
1 amazon/dynamodb-local:1.13.1
1 ghcr.io/dexidp/dex:v2.38.0
1 public.ecr.aws/aws-containers/retail-store-sample-assets:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-cart:0.7.0
1 public.ecr.aws/aws-containers/retail-store-sample-catalog:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-checkout:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-orders:0.4.0
1 public.ecr.aws/aws-containers/retail-store-sample-ui:0.4.0
1 public.ecr.aws/bitnami/rabbitmq:3.11.1-debian-11-r0
2 public.ecr.aws/docker/library/mysql:8.0
1 public.ecr.aws/docker/library/redis:6.0-alpine
1 public.ecr.aws/docker/library/redis:7.0.15-alpine
2 public.ecr.aws/eks-distro/kubernetes-csi/external-provisioner:v3.6.3-eks-1-29-2
8 public.ecr.aws/eks-distro/kubernetes-csi/livenessprobe:v2.11.0-eks-1-29-2
6 public.ecr.aws/eks-distro/kubernetes-csi/node-driver-registrar:v2.9.3-eks-1-29-2
2 public.ecr.aws/eks/aws-load-balancer-controller:v2.7.1
2 public.ecr.aws/karpenter/controller:0.37.0@sha256:157f478f5db1fe999f5e2d27badcc742bf51cc470508b3cebe78224d0947674f
5 quay.io/argoproj/argocd:v2.10.0
1 registry.k8s.io/metrics-server/metrics-server:v0.7.0[3.1 데이터부 - 관리형노드그룹] Upgrading EKS Managed Node groups
- 관리형 노드 그룹 : 업그레이드 전략 - 기존 EKS 관리 노드 그룹 업데이드(인플레이스) vs 새로운 EKS 관리 노드 그룹으로 마이그레이션(블루-그린)
- Amazon EKS 관리형 노드 그룹은 Amazon EKS 클러스터의 노드(Amazon EC2 인스턴스) 프로비저닝 및 수명 주기 관리를 자동화합니다.
- Amazon EKS 관리형 노드 그룹을 사용하면 Kubernetes 애플리케이션을 실행하기 위한 컴퓨팅 용량을 제공하는 Amazon EC2 인스턴스를 별도로 프로비저닝하거나 등록할 필요가 없습니다. 단일 작업으로 클러스터에 대한 노드를 생성, 자동 업데이트 또는 종료할 수 있습니다. 노드 업데이트 및 종료는 노드를 자동으로 비워 애플리케이션이 계속 사용 가능한 상태를 유지하도록 합니다.
- 모든 관리 노드는 Amazon EKS에서 관리하는 Amazon EC2 Auto Scaling 그룹의 일부로 프로비저닝됩니다. 인스턴스와 Auto Scaling 그룹을 포함한 모든 리소스는 AWS 계정 내에서 실행됩니다. 각 노드 그룹은 사용자가 정의한 여러 가용성 영역에서 실행됩니다.
[3.1 데이터부 - 관리형노드그룹] 관리형 노드 그룹 업데이트를 시작하면 Amazon EKS가 자동으로 노드를 업데이트하여 아래 설명된 대로 4가지 단계를 완료합니다.
관리 노드 그룹 업그레이드도 완전히 자동화되어 점진적인 롤링 업데이트로 구현됩니다.
- 새 노드는 EC2 자동 스케일링 그룹에 프로비저닝되고 클러스터에 합류하며, as old nodes는 cordoned, drained, and removed
- 기본적으로 새 노드는 최신 EKS 최적화 AMI(Amazon Machine Image) 또는 선택적으로 사용자 지정 AMI를 사용합니다.
참고로, 사용자 지정 AMI를 사용할 때는 업데이트된 이미지를 직접 만들어야 하므로 노드 그룹 업그레이드의 일환으로 업데이트된 Launch Template 버전이 필요합니다.
- 관리형 노드 그룹 업데이트를 시작하면 Amazon EKS가 자동으로 노드를 업데이트하여 아래 설명된 대로 4가지 단계를 완료합니다.
- 설정 단계:
- 노드 그룹과 연결된 자동 스케일링 그룹에 대한 새로운 Amazon EC2 launch template version을 생성합니다.
- The new launch template version은 업데이트에 target AMI 또는 custom launch template version for the update 를 사용합니다.
- Auto Scaling group을 최신 실행 템플릿 버전latest launch template version을 사용하도록 업데이트합니다.
- 노드 그룹에 대한 updateConfig 속성을 사용하여 병렬로 업그레이드할 최대 노드 수를 결정합니다.
- The maximum unavailable has a quota of 100 nodes. 기본값은 1개 노드입니다.
- 확장 단계: 확장 단계에는 다음 단계가 있습니다.
- 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 더 큰 크기로 증가시킵니다. It increments the Auto Scaling Group's maximum size and desired size by the larger of either
- 자동 확장 그룹이 배포된 가용성 영역 수의 최대 2배. Up to twice the number of Availability Zones that the Auto Scaling group is deployed in.
- 업그레이드가 불가능 한 최대 한도입니다. The maximum unavailable of upgrade.
- 자동 확장 그룹을 확장한 후 최신 구성을 사용하는 노드가 노드 그룹에 있고 준비되었는지 확인합니다.
- 그런 다음 노드를 예약 불가능으로 표시하여 새 Pod를 예약하지 않도록 합니다. It then marks nodes as un-schedulable to avoid scheduling new Pods.
- 또한 노드를 node.kubernetes.io/exclude-from-external-load-balancers=true 로 레이블하여 노드를 종료하기 전에 로드 밸런서에서 노드를 제거합니다. It also labels nodes with node.kubernetes.io/exclude-from-external-load-balancers=true to remove the nodes from load balancers before terminating the nodes.
- 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 더 큰 크기로 증가시킵니다. It increments the Auto Scaling Group's maximum size and desired size by the larger of either
- 업그레이드 단계:* 업그레이드 단계는 다음과 같은 단계로 구성됩니다.
- 노드 그룹에 대해 구성된 최대 사용 불가능 개수까지 업그레이드가 필요한 노드를 무작위로 선택합니다.
- It randomly selects a node that needs to be upgraded, up to the maximum unavailable configured for the node group.
- 노드에서 Pod를 비웁니다. Pod가 15분 이내에 노드를 떠나지 않고 강제 플래그가 없으면 업그레이드 단계는 PodEvictionFailure 오류
- It drains the Pods from the node. If the Pods don't leave the node within 15 minutes and there's no force flag, the upgrade phase fails with a PodEvictionFailure error. For this scenario, you can apply the force flag with the update-nodegroup-version request to delete the Pods.
- 로 실패합니다 . 이 시나리오에서는 update-nodegroup-version 요청과 함께 강제 플래그를 적용하여 Pod를 삭제할 수 있습니다.
- 모든 Pod가 퇴거된 후 노드를 봉쇄하고 60초 동안 기다립니다. 이는 서비스 컨트롤러가 이 노드에 새로운 요청을 보내지 않고 이 노드를 활성 노드 목록에서 제거하기 위해 수행됩니다.
- It cordons the node after every Pod is evicted and waits for 60 seconds. This is done so that the service controller doesn't send any new requests to this node and removes this node from its list of active nodes.
- cordoned 노드에 대한 자동 확장 그룹에 종료 요청을 보냅니다.
- It sends a termination request to the Auto Scaling Group for the cordoned node.
- 이전 버전의 실행 템플릿을 사용하여 배포된 노드 그룹에 노드가 없을 때까지 이전 업그레이드 단계를 반복합니다.
- It repeats the previous upgrade steps until there are no nodes in the node group that are deployed with the earlier version of the launch template.
- 노드 그룹에 대해 구성된 최대 사용 불가능 개수까지 업그레이드가 필요한 노드를 무작위로 선택합니다.
- 축소 단계: 축소 단계에서는 자동 크기 조정 그룹의 최대 크기와 원하는 크기를 하나씩 감소시켜 업데이트가 시작되기 전 값으로 돌아갑니다.
- 축소 단계는 자동 스케일링 그룹의 최대 크기와 원하는 크기를 하나씩 줄여 업데이트가 시작되기 전의 값으로 돌아갑니다.
- 설정 단계:
실습 방법 3 : Terraform , 해당 방법으로 실제 업그레이드 실행! 20분 소요 실습 포함
이제 우리는 마지막 랩에서 eks 클러스터 제어 평면을 버전 1.26으로 업그레이드했습니다.
- 다음 단계로, 우리는 워커 노드를 업그레이드해야 합니다. 이 랩에서 우리는 이 클러스터에 대해 프로비저닝된 관리 노드 그룹을 업그레이드할 것입니다.
- 우리는 접두사가 있는 두 개의 관리 노드 그룹을 가지고 있습니다
#
cat base.tf
...
eks_managed_node_group_defaults = {
cluster_version = var.mng_cluster_version
}
eks_managed_node_groups = { # 버전 명시가 없으면, 상단 default 버전 사용 -> variables.tf 확인
initial = {
instance_types = ["m5.large", "m6a.large", "m6i.large"]
min_size = 2
max_size = 10
desired_size = 2
update_config = {
max_unavailable_percentage = 35
}
}
blue-mng={
instance_types = ["m5.large", "m6a.large", "m6i.large"]
cluster_version = "1.25"
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
labels = {
type = "OrdersMNG"
}
subnet_ids = [module.vpc.private_subnets[0]]
taints = [
{
key = "dedicated"
value = "OrdersApp"
effect = "NO_SCHEDULE"
}
]
}관리 노드 그룹 업데이트를 수행할 때 다음 시나리오를 보여드리겠습니다.
- 특정 AMI ID 사용(사용자 정의 AMI와 같음) Using specific AMI ID (like custom AMIs)
- 지정된 K8s 버전에 대한 기본 AMI 사용 Using default AMI for given K8s version
이 실험실의 전제 조건으로 먼저 사용자 지정 AMI를 사용하여 신규 관리 노드 그룹을 생성해 보겠습니다.
이를 위해 kubernetes 버전 1.25의 ami_id를 가져오고 variable.tf 파일의 변수 ami_id를 결과 값으로 대체해 보겠습니다.
- 1.25의 ami_id를 가져오기
ec2-user:~/environment/terraform:$ aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Blueprint,Values=eksworkshop-eksctl" --output table
----------------------------------------------
| DescribeInstances |
+------------------+-------------------------+
| default-selfmng | ami-0ee947a6f4880da75 |
| blue-mng | ami-0078a0f78fafda978 |
| initial | ami-0078a0f78fafda978 |
| default-selfmng | ami-0ee947a6f4880da75 |
| initial | ami-0078a0f78fafda978 |
+------------------+-------------------------+
ec2-user:~/environment/terraform:$ kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami
ip-10-0-27-83.us-west-2.compute.internal Ready <none> 46h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-6-49.us-west-2.compute.internal Ready <none> 46h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-8-255.us-west-2.compute.internal Ready <none> 46h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ec2-user:~/environment/terraform:$ aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.25/amazon-linux-2/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text
ami-0078a0f78fafda978- teraform/variables.tf 에서 ami_id 부분 변경
- ami-0078a0f78fafda978 입력

- teraform/base.tf에 해당 부분 추가
custom = {
instance_types = ["t3.medium"]
min_size = 1
max_size = 2
desired_size = 1
update_config = {
max_unavailable_percentage = 35
}
ami_id = try(var.ami_id)
enable_bootstrap_user_data = true
}
- terraform apply 후 확인
ec2-user:~/environment/terraform:$ while true; do aws autoscaling describe-auto-scaling-groups --query 'AutoScalingGroups[*].AutoScalingGroupName' --output json | jq; echo ; kubectl get node -L eks.amazonaws.com/nodegroup; echo; date ; echo ; kubectl get node -L eks.amazonaws.com/nodegroup-image | grep ami; echo; sleep 1; echo; done
[
"default-selfmng-20250330052212962100000029",
"eks-blue-mng-2025033005221298520000002c-24caf2c0-0dd1-662b-dc02-1757a879aed8",
"eks-custom-20250401043828098700000003-60caf7d2-6326-2ea5-cd9c-1caccf31971c",
"eks-initial-2025033005221298110000002a-32caf2c0-0dd0-cba3-2a6c-ac3298884e1e"
]
NAME STATUS ROLES AGE VERSION NODEGROUP
fargate-ip-10-0-2-200.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-2d5f260
ip-10-0-22-6.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-59bf375
ip-10-0-27-83.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-59bf375 initial-2025033005221298110000002a
ip-10-0-29-248.us-west-2.compute.internal Ready <none> 30m v1.25.16-eks-59bf375
ip-10-0-34-3.us-west-2.compute.internal Ready <none> 35m v1.25.16-eks-59bf375
ip-10-0-6-49.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-59bf375 initial-2025033005221298110000002a
ip-10-0-7-91.us-west-2.compute.internal Ready <none> 34m v1.25.16-eks-59bf375 custom-20250401043828098700000003
ip-10-0-8-255.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-59bf375 blue-mng-2025033005221298520000002c
Tue Apr 1 05:14:25 UTC 2025
ip-10-0-27-83.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-6-49.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-7-91.us-west-2.compute.internal Ready <none> 34m v1.25.16-eks-59bf375 ami-0078a0f78fafda978
ip-10-0-8-255.us-west-2.compute.internal Ready <none> 47h v1.25.16-eks-59bf375 ami-0078a0f78fafda978ec2-user:~/environment/terraform:$ kubectl describe node ip-10-0-7-91.us-west-2.compute.internal
Name: ip-10-0-7-91.us-west-2.compute.internal
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/instance-type=t3.medium
beta.kubernetes.io/os=linux
eks.amazonaws.com/capacityType=ON_DEMAND
eks.amazonaws.com/nodegroup=custom-20250401043828098700000003
eks.amazonaws.com/nodegroup-image=ami-0078a0f78fafda978
eks.amazonaws.com/sourceLaunchTemplateId=lt-08fcf58bba84a117a
eks.amazonaws.com/sourceLaunchTemplateVersion=2
failure-domain.beta.kubernetes.io/region=us-west-2
failure-domain.beta.kubernetes.io/zone=us-west-2a
k8s.io/cloud-provider-aws=a94967527effcefb5f5829f529c0a1b9
kubernetes.io/arch=amd64
kubernetes.io/hostname=ip-10-0-7-91.us-west-2.compute.internal
kubernetes.io/os=linux
node.kubernetes.io/instance-type=t3.medium
topology.ebs.csi.aws.com/zone=us-west-2a
topology.kubernetes.io/region=us-west-2
topology.kubernetes.io/zone=us-west-2a
Annotations: alpha.kubernetes.io/provided-node-ip: 10.0.7.91
csi.volume.kubernetes.io/nodeid: {"ebs.csi.aws.com":"i-0a2b5b730dc766a17","efs.csi.aws.com":"i-0a2b5b730dc766a17"}
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Tue, 01 Apr 2025 04:39:42 +0000
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: ip-10-0-7-91.us-west-2.compute.internal
AcquireTime: <unset>
RenewTime: Tue, 01 Apr 2025 05:15:47 +0000
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Tue, 01 Apr 2025 05:11:17 +0000 Tue, 01 Apr 2025 04:39:41 +0000 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Tue, 01 Apr 2025 05:11:17 +0000 Tue, 01 Apr 2025 04:39:41 +0000 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Tue, 01 Apr 2025 05:11:17 +0000 Tue, 01 Apr 2025 04:39:41 +0000 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Tue, 01 Apr 2025 05:11:17 +0000 Tue, 01 Apr 2025 04:39:57 +0000 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 10.0.7.91
Hostname: ip-10-0-7-91.us-west-2.compute.internal
InternalDNS: ip-10-0-7-91.us-west-2.compute.internal
Capacity:
attachable-volumes-aws-ebs: 25
cpu: 2
ephemeral-storage: 20959212Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3943300Ki
pods: 17
Allocatable:
attachable-volumes-aws-ebs: 25
cpu: 1930m
ephemeral-storage: 18242267924
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3388292Ki
pods: 17
System Info:
Machine ID: ec21be5b08149fc5de95d2fc525e28be
System UUID: ec21be5b-0814-9fc5-de95-d2fc525e28be
Boot ID: 8ecb62eb-c198-4877-8a85-e67c51b6e61e
Kernel Version: 5.10.234-225.910.amzn2.x86_64
OS Image: Amazon Linux 2
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.7.25
Kubelet Version: v1.25.16-eks-59bf375
Kube-Proxy Version: v1.25.16-eks-59bf375
ProviderID: aws:///us-west-2a/i-0a2b5b730dc766a17
Non-terminated Pods: (6 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system aws-node-npjvb 50m (2%) 0 (0%) 0 (0%) 0 (0%) 36m
kube-system ebs-csi-controller-6b575b5f4d-nzkdc 60m (3%) 0 (0%) 240Mi (7%) 1536Mi (46%) 35m
kube-system ebs-csi-node-k67g6 30m (1%) 0 (0%) 120Mi (3%) 768Mi (23%) 36m
kube-system efs-csi-controller-5d74ddd947-xkrrm 0 (0%) 0 (0%) 0 (0%) 0 (0%) 35m
kube-system efs-csi-node-vpn2t 0 (0%) 0 (0%) 0 (0%) 0 (0%) 36m
kube-system kube-proxy-dvxc7 100m (5%) 0 (0%) 0 (0%) 0 (0%) 36m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 240m (12%) 0 (0%)
memory 360Mi (10%) 2304Mi (69%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
attachable-volumes-aws-ebs 0 0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Starting 36m kube-proxy
Normal Starting 36m kubelet Starting kubelet.
Warning InvalidDiskCapacity 36m kubelet invalid capacity 0 on image filesystem
Normal NodeHasSufficientMemory 36m (x2 over 36m) kubelet Node ip-10-0-7-91.us-west-2.compute.internal status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 36m (x2 over 36m) kubelet Node ip-10-0-7-91.us-west-2.compute.internal status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 36m (x2 over 36m) kubelet Node ip-10-0-7-91.us-west-2.compute.internal status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 36m kubelet Updated Node Allocatable limit across pods
Normal RegisteredNode 36m node-controller Node ip-10-0-7-91.us-west-2.compute.internal event: Registered Node ip-10-0-7-91.us-west-2.compute.internal in Controller
Normal NodeReady 35m kubelet Node ip-10-0-7-91.us-west-2.compute.internal status is now: NodeReady
ec2-user:~/environment/terraform:$
eks_managed_node_group_defaults 클러스터_버전의 값은 variable.tf 의 변수 mng_cluster_version에 정의되어 있습니다.
- variable.tf 에서 변수 mng_cluster_version을 "1.25"에서 "1.26"으로 변경하고 테라폼을 실행하면 됩니다.
- Lets upgrade the initial and custom managed node groups to latest cluster version.
#
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region $AWS_REGION --query "Parameter.Value" --output text
ami-086414611b43bb691
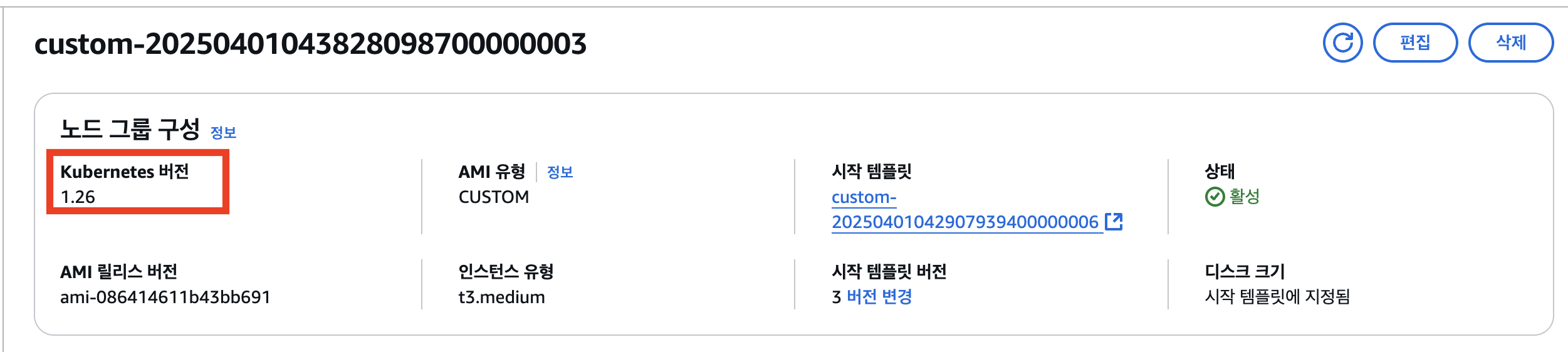
완료되면 Amazon EKS 콘솔에서 initial and custom manage node groups의 변경 사항을 확인할 수 있습니다.
초기 및 맞춤형 관리 노드그룹 kubernetes 버전이 1.26임을 알 수 있습니다.


terraform apply 완료후

[3.2 데이터부 - 카펜터노드] Upgrading Karpenter managed nodes
Karpenter는 집계된 CPU, 메모리, 볼륨 요청 및 기타 Kubernetes 스케줄링 제약(예: 친화도 및 포드 토폴로지 확산 제약)을 기반으로 스케줄링 불가능한 포드에 대응하여 적절한 크기의 노드를 제공하는 오픈 소스 클러스터 오토스케일러로, 인프라 관리를 간소화합니다.
- amiFamily of Custom을 선택하면 어떤 사용자 지정 AMI를 사용할지 Karpenter에 알려주는 amiSelectorTerms를 지정해야 합니다.
- Karpenter는 Karpenter를 통해 프로비저닝된 Kubernetes 작업자 노드를 패치하는 데 Drift 또는 타이머(expireAfter)와 같은 기능을 사용합니다.
현재 Karpenter에서는 EC2NodeClass 리소스가 amiFamily 값 AL2, AL2023, Bottlerocket, Ubuntu, Windows2019, Windows2022 및 Custom을 지원합니다.
Drift
- Karpenter는 롤링 배포 후 Drift를 사용하여 Kubernetes 노드를 업그레이드합니다.
- Karpenter를 통해 프로비저닝된 Kubernetes 노드가 원하는 사양에서 벗어난 경우, Karpenter는 먼저 새로운 노드를 프로비저닝하고 이전 노드에서 포드를 제거한 다음 종료합니다.
- 노드가 디프로비전됨에 따라 노드는 새로운 포드 스케줄링을 방지하기 위해 코드화되고 Kubernetes Eviction API를 사용하여 포드가 퇴거됩니다.
- EC2NodeClass에서는 amiFamily가 필수 필드이며, 자신의 AMI 값인 EKS 최적화 AMI를 사용할 수 있습니다.
- AMI의 드리프트는 두 가지 동작이 있으며, 아래에 자세히 설명되어 있습니다.
1. Drift with specified AMI values 지정된 AMI 값을 사용한 드리프트:
2. Drift with Amazon EKS optimized AMIs Amazon EKS 최적화 AMI를 사용한 드리프트:
기본 노드풀 및 ec2 nod 클래스의 출력에서 다음을 확인할 수 있습니다:
- 이 노드풀을 사용하면 Spec.Druption.Budgets에 따라 중단 시 10% 노드가 재활용되는 기본 예산이 적용됩니다.
- 이 노드풀에 대해 카르펜터를 통해 프로비저닝된 노드에는 Team: 체크아웃 라벨이 Spec.Template.Metadata.Labels에 따라 표시되며, 이들 노드에는 Spec.Template.Spec.Taints에 따라 태그가 적용됩니다.
- 이 노드풀은 Spec.Template.Spec.NodeClass Ref에 따라 기본 EC2NodeClass를 사용하고 있습니다.
- 이 기본 EC2NodeClass 사양을 사용하여 노드풀은 아미드 ami-03db5eb 228232c943을 사용하여 노드를 프로비저닝하고 있습니다.
node selector label team=checkou와 default nodepool을 통해 프로비저닝된 노드에 tolerations to tolerate taints를 가진 체크아웃 앱 포드를 프로비저닝했습니다.
Checkout 앱은 포드에 지속적인 볼륨이 부착된 stateful 애플리케이션입니다.
이 실험실에서는 상태 저장 워크로드를 실행하는 카펜터를 통해 프로비저닝된 노드를 업그레이드하는 방법을 시연할 것입니다.
이를 위해 kubernetes 버전 1.26용으로 빌드된 AMI ID를 가진 eks-gitops-repo/apps/karpenter 폴더의 기본 eks-ec2nc.yaml 파일에서 AMI ID를 변경하고 eks-gitops-repo의 변경 사항을 푸시할 것입니다.
Argo-CD를 통해 변경 사항이 동기화되면 Karpenter 컨트롤러는 노드가 드리프트되었음을 자동으로 감지하여 드리프트된 노드를 최신 구성의 노드로 프로비저닝하는 데 방해가 될 것입니다.
논의한 바와 같이, 중단되는 노드의 수를 제어하거나 특정 시간에만 노드를 중단시키는 시나리오가 있습니다.
이 실험실에서는 Karpenter가 다른 노드를 프로비저닝하여 예정에 없던 체크아웃 포드를 실행할 수 있도록 체크아웃 앱을 확장할 것입니다.
그런 다음 한 번에 하나씩 노드를 중단시키기 위한 PDB을 정의합니다.
Karpenter 컨트롤러는 한 번에 하나씩 드리프트를 통해 노드를 중단합니다.
카펜터 노드 Upgrade 실습
#
aws ec2 describe-instances --query "Reservations[*].Instances[*].[Tags[?Key=='Name'].Value | [0], ImageId]" --filters "Name=tag:Blueprint,Values=eksworkshop-eksctl" --output table
# 기본 노드풀을 통해 프로비저닝된 노드가 버전 v1.25.16-eks-59bf375에 있는 것을 확인할 수 있습니다.
kubectl get nodes -l team=checkout
NAME STATUS ROLES AGE VERSION
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 24h v1.25.16-eks-59bf375
# Check taints applied on the nodes.
kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"
kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints[?(@.effect=='NoSchedule')]}{\"\n\"}{end}"
ip-10-0-39-95.us-west-2.compute.internal {"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}
#
kubectl get pods -n checkout -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
checkout-558f7777c-fs8dk 1/1 Running 0 24h 10.0.39.105 ip-10-0-39-95.us-west-2.compute.internal <none> <none>
checkout-redis-f54bf7cb5-whk4r 1/1 Running 0 24h 10.0.41.7 ip-10-0-39-95.us-west-2.compute.internal <none> <none>
# 모니터링
kubectl get nodeclaim
kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"
kubectl get pods -n checkout -o wide
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done결제 앱 포드가 카펜터에서 프로비저닝한 노드에서 실행되고 있는 것을 볼 수 있습니다.
체크아웃 애플리케이션을 확장해 보겠습니다. 이를 위해 아래와 같이 eks-gitops-repo/apps/checkout 폴더의 deposition.yaml 파일에서 복제본을 1에서 15으로 변경합니다.
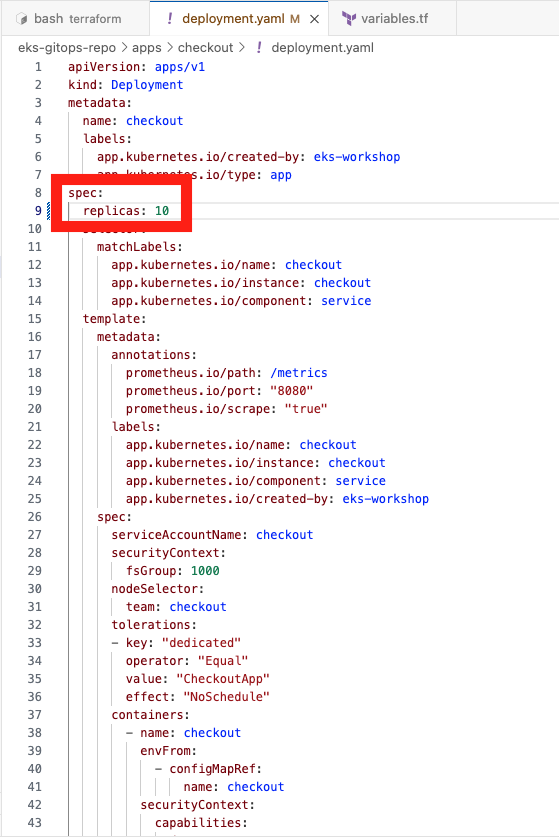
변경이 완료되면 저장소에 변경 사항을 커밋하고 푸시한 후 Argo-cd가 변경 사항을 동기화 할 때까지 기다립니다.
#
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
#
cd ~/environment/eks-gitops-repo
git add apps/checkout/deployment.yaml
git commit -m "scale checkout app"
git push --set-upstream origin main
# You can force the sync using ArgoCD console or following command:
argocd app sync checkout
# LIVE(k8s)에 직접 scale 실행
kubectl scale deploy checkout -n checkout --replicas 10
# 현재는 1.25.16 2대 사용 중 확인
# Karpenter will scale looking at the aggregate resource requirements of unscheduled pods. We will see we have now two nodes provisioned via karpenter.
kubectl get nodes -l team=checkout
NAME STATUS ROLES AGE VERSION
ip-10-0-24-213.us-west-2.compute.internal Ready <none> 62s v1.25.16-eks-59bf375
ip-10-0-39-95.us-west-2.compute.internal Ready <none> 24h v1.25.16-eks-59bf375
# Lets get the ami id for the AMI build for kubernetes version 1.26.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region ${AWS_REGION} --query "Parameter.Value" --output text
ami-086414611b43bb691
Tue Apr 1 14:04:09 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-7fzdk m6i.large us-west-2b ip-10-0-22-6.us-west-2.compute.internal True 2d8h
default-m9xrv c5.large us-west-2a ip-10-0-4-12.us-west-2.compute.internal True 58s
NAME STATUS ROLES AGE VERSION
ip-10-0-22-6.us-west-2.compute.internal Ready <none> 2d8h v1.25.16-eks-59bf375
ip-10-0-4-12.us-west-2.compute.internal Ready <none> 31s v1.25.16-eks-59bf375
ip-10-0-22-6.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-4-12.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
checkout-558f7777c-6lrnk 1/1 Running 0 62s 10.0.19.185 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
checkout-558f7777c-7rpxn 1/1 Running 0 62s 10.0.6.215 ip-10-0-4-12.us-west-2.compute.internal <none> <none>
checkout-558f7777c-j4v8g 1/1 Running 0 62s 10.0.7.234 ip-10-0-4-12.us-west-2.compute.internal <none> <none>
checkout-558f7777c-jqnct 1/1 Running 0 62s 10.0.5.29 ip-10-0-4-12.us-west-2.compute.internal <none> <none>
checkout-558f7777c-ppwv7 1/1 Running 0 62s 10.0.20.68 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
checkout-558f7777c-rqwzs 1/1 Running 0 63s 10.0.19.40 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
checkout-558f7777c-rw2cj 1/1 Running 0 62s 10.0.22.170 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
checkout-558f7777c-t2fft 1/1 Running 0 63s 10.0.18.147 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
checkout-558f7777c-v4274 1/1 Running 0 62s 10.0.29.4 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
checkout-558f7777c-zlzjc 1/1 Running 0 2d8h 10.0.19.176 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
checkout-redis-f54bf7cb5-vswzf 1/1 Running 0 2d8h 10.0.28.6 ip-10-0-22-6.us-west-2.compute.internal <none> <none>
Tue Apr 1 14:04:14 UTC 2025
NAME TYPE ZONE NODE READY AGE
default-7fzdk m6i.large us-west-2b ip-10-0-22-6.us-west-2.compute.internal True 2d8h
default-m9xrv c5.large us-west-2a ip-10-0-4-12.us-west-2.compute.internal True 64s
NAME STATUS ROLES AGE VERSION
ip-10-0-22-6.us-west-2.compute.internal Ready <none> 2d8h v1.25.16-eks-59bf375
ip-10-0-4-12.us-west-2.compute.internal Ready <none> 37s v1.25.16-eks-59bf375
ip-10-0-22-6.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}]
ip-10-0-4-12.us-west-2.compute.internal [{"effect":"NoSchedule","key":"dedicated","value":"CheckoutApp"}][파일 수정] We are making following changes in the default-ec2nc.yaml and default-np.yaml in eks-gitops-repo/app/karpenter folder as shown below.
kubectl get ec2nodeclass default -o yaml | grep 'id: ami-' | uniq
- id: ami-0ee947a6f4880da75
kubectl get nodepool default -o yaml
...
spec:
disruption:
budgets:
- nodes: "1"
consolidationPolicy: WhenUnderutilized
expireAfter: Never
limits:
...

#
while true; do kubectl get nodeclaim; echo ; kubectl get nodes -l team=checkout; echo ; kubectl get nodes -l team=checkout -o jsonpath="{range .items[*]}{.metadata.name} {.spec.taints}{\"\n\"}{end}"; echo ; kubectl get pods -n checkout -o wide; echo ; date; sleep 1; echo; done
# 10분 소요 (예상) 실습 포함
cd ~/environment/eks-gitops-repo
git add apps/karpenter/default-ec2nc.yaml apps/karpenter/default-np.yaml
git commit -m "disruption changes"
git push --set-upstream origin main
argocd app sync karpenter
# Once Argo CD sync the karpenter app, we can see the disruption event in karpenter controller logs. It will then provision new nodes with kubernetes version 1.26 and delete the old nodes.
kubectl -n karpenter logs deployment/karpenter -c controller --tail=33 -f
혹은
kubectl stern -n karpenter deployment/karpenter -c controller
# Lets get the ami id for the AMI build for kubernetes version 1.26.
aws ssm get-parameter --name /aws/service/eks/optimized-ami/1.26/amazon-linux-2/recommended/image_id \
--region ${AWS_REGION} --query "Parameter.Value" --output text
ami-086414611b43bb691
카르펜터 컨트롤러 로그에서 노드 ip-10-0-11-205.us -west-2.compute.internal과 ip-10-0-47-152.us -west-2.compute.internal이 하나씩 표류하는 것을 볼 수 있습니다.
새 노드를 가져와서 이 노드에서 체크아웃 앱 포드가 실행되고 있는지 확인해 보겠습니다. 이제 노드가 v1.26.15-eks-1552ad0 버전에 있는지 확인할 수 있
'DevOps' 카테고리의 다른 글
| [AWS EKS] (26) EKS 스터디 10주차 ( Vault ) (0) | 2025.04.11 |
|---|---|
| [AWS EKS] (25) EKS 스터디 8주차 (Blue-Green Upgrade) (1) | 2025.04.02 |
| [AWS EKS] (23) EKS 스터디 8주차 (Amazon EKS Upgrades: Strategies and Best Practices) (1) | 2025.03.31 |
| [AWS EKS] (22) EKS 스터디 8주차 ( jenkins + harbor+ agrocd - CICD ) (0) | 2025.03.29 |
| [AWS EKS] (21) EKS 스터디 8주차 ( Gogs+ jenkins - CICD ) (1) | 2025.03.29 |



