CloudNet@팀의 EKS 스터디 AEWS 2기에 작성된 자료를 토대로 작성합니다.
프로메테우스/그라파나 활용시 운영환경에서 어떻게 대시보드를 구성하고 알람을 설정하여
해당 알람이 발생시 어떤식으로 조치하는가 간략하게 소개해보려 합니다.
환경마다 중요시 하는 메트릭들이 상당히 차이가 있겠지만
각 워커노드의 CPU 사용률과 같은 경우는 공통적으로 사용하기 때문에
해당 부분을 대표적으로 다루도록 하겠습니다.
CPU 사용률 대시보드 쿼리 설정 및 알람 설정
- 노드 별 CPU 사용률
목표: 기준을 80%로 지정해두고 해당 기준을 넘어갈 경우 Alert를 슬랙으로 전달합니다.

sum by (instance) (irate(node_cpu_seconds_total{mode!~"guest.*|idle|iowait", instance="$instance"}[5m]))- grafana Alert 설정 : 점3개 선택해서 Edit

- Alert 선택

- contact Point 미리 만들어두기

- 80% 이상 인 경우 알람을 받기 위해서 먼저 C 항목에 ‘Threshold’ 선택하고
- ‘IS ABOVE ’80’를 입력합니다.
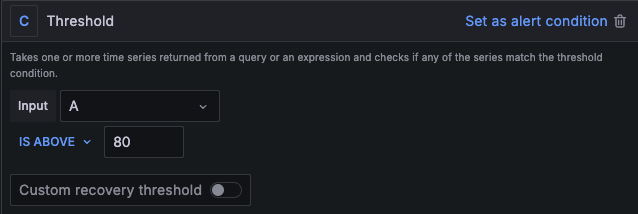
- 다음으로 B 항목에 ‘Reduce’의 Max 옵션을 선택합니다. 최대 사용률이 80% 초과인 경우 알람을 받도록 설정합니다.
- Input은 ‘A’ 즉 앞에서 결과값이 나오는 Query를 선택한다.

- 다음은 알람 확인 주기 입니다. 몇 분 간격(evaluation)으로 얼마나(for) 지속되면 알람을 보낼 것인지 설정합니다. 필자는 아래와 같이 1분 간격으로 1분 동안 지속되면 알람을 보내도록 설정하였습니다.

리소스 부족 상황이거나 IO wait로 인해 CPU가 정상적으로 작동하지 못하는 상황으로 추정
선제적으로 리소스 확보 한 후 상세 점검합니다.
1. 해당 클러스터의 서비스 담당자에게 메일 발송
안녕하세요. OOO 책임 연구원님 클라우드 운영센터 OOO 입니다. KST 3/1일 12시 13분 경 ccs-au-prd 클러스터의 CPU 사용률이 80퍼 이상 사용중으로 알람 발생 하여 공유드립니다. 서비스 이상 있는지 확인 부탁드리며, 노드 증설 가능 여부 체크 부탁드립니다.  |
2. 사용자가 서비스 영향도가 있다고 판단하면 VM 재기동 또는 노드 스케일링
| 안녕하세요. OOO 책임 연구원님 클라우드 운영센터 ㅇㅁㄴ입니다. 현재 노드 증설 가능한 리소스 풀 확인 하였습니다. ap-northeast-2a-svchub 리소스 풀에 32 core VM 노드 템플릿 4개 세트 증설 가능합니다. 노드 증설 부탁 드립니다. 감사합니다. |
3. top , cpu load, io wait ,vmstat 확인
[root@ip-192-168-1-163 ~]# vmstat 1 10
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 308844 2644 2592304 0 0 2 31 59 45 3 1 93 0 3
0 0 0 308844 2644 2592424 0 0 0 0 1060 1672 3 2 94 0 2
0 0 0 308844 2644 2592524 0 0 0 0 2055 3582 4 1 92 0 4
0 0 0 308844 2644 2592544 0 0 0 0 1943 3554 1 0 97 0 2
0 0 0 308844 2644 2592556 0 0 0 0 1742 3149 2 0 97 0 2
0 0 0 308088 2644 2592564 0 0 0 0 2148 4278 10 1 83 0 5
0 0 0 304812 2644 2592576 0 0 0 0 1576 3191 2 3 91 0 4
0 0 0 304560 2644 2592588 0 0 0 0 1512 2790 4 2 91 0 3
0 0 0 304560 2644 2592592 0 0 0 0 1031 1884 2 0 96 0 3
0 0 0 304056 2644 2592604 0 0 0 12 1302 2630 3 1 94 0 2
4. iotop 을 통해 diskio 실시간 정보 확보 ( 특정한 process의 디스크 사용이 큰지 확인)
[root@ip-192-168-1-163 ~]# iotop -b -o -d 1 >> iotop.txt
... 중략
Total DISK READ: 0.00 B/s | Total DISK WRITE: 109.47 K/s
Current DISK READ: 0.00 B/s | Current DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO COMMAND
b' 75610 be/4 ec2-user 0.00 B/s 101.65 K/s ?unavailable? prometheus --web.console.templates=/etc/prometheus/consoles --web.console.libraries=/etc/prometheus/console_libraries --config.file=/etc/prometheus/config_out/prometheus.env.yaml --web.enable-lifecycle --web.external-url=http://prometheus.cubicle.zone/ --web.route-prefix=/ --storage.tsdb.retention.time=5d --storage.tsdb.retention.size=10GiB --storage.tsdb.path=/prometheus --storage.tsdb.wal-compression --web.config.file=/etc/prometheus/web_config/web-config.yaml'
b' 225951 be/4 ec2-user 0.00 B/s 7.82 K/s ?unavailable? prometheus --web.console.templates=/etc/prometheus/consoles --web.console.libraries=/etc/prometheus/console_libraries --config.file=/etc/prometheus/config_out/prometheus.env.yaml --web.enable-lifecycle --web.external-url=http://prometheus.cubicle.zone/ --web.route-prefix=/ --storage.tsdb.retention.time=5d --storage.tsdb.retention.size=10GiB --storage.tsdb.path=/prometheus --storage.tsdb.wal-compression --web.config.file=/etc/prometheus/web_config/web-config.yaml'5. netstat을 통해 network io 실시간 정보 확인
[root@ip-192-168-1-163 ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eni371be3d8ed8 9001 381500 0 1 0 419150 0 0 0 BMRU
eni4c5ca41b167 9001 878197 0 1 0 997406 0 0 0 BMRU
enicd44662f22d 9001 86416 0 1 0 94168 0 0 0 BMRU
enide53aad20e7 9001 1758021 0 1 0 1674553 0 0 0 BMRU
enie56f4c00502 9001 4066939 0 1 0 4188603 0 0 0 BMRU
eniec9e2d62a25 9001 1314693 0 1 0 1340435 0 0 0 BMRU
ens5 9001 4154947 0 0 0 4002037 0 0 0 BMRU
ens6 9001 4783096 0 0 0 2921927 0 0 0 BMRU
ens7 9001 2713 0 0 0 2772 0 0 0 BMRU
lo 65536 1199779 0 0 0 1199779 0 0 0 LRU
# iperf3 테스트 후
[root@ip-192-168-1-163 ~]# netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eni371be3d8ed8 9001 382375 0 1 0 420072 0 0 0 BMRU
eni4c5ca41b167 9001 879533 0 1 0 998870 0 0 0 BMRU
enicd44662f22d 9001 86546 0 1 0 94308 0 0 0 BMRU
enide53aad20e7 9001 1761138 0 1 0 1677486 0 0 0 BMRU
enie56f4c00502 9001 4073921 0 1 0 4196096 0 0 0 BMRU
eniec9e2d62a25 9001 1316711 0 1 0 1342496 0 0 0 BMRU
ens5 9001 8143152 0 0 0 5101219 0 0 0 BMRU
ens6 9001 4791450 0 0 0 2926810 0 0 0 BMRU
ens7 9001 2717 0 0 0 2776 0 0 0 BMRU
lo 65536 1201824 0 0 0 1201824 0 0 0 LRU<테스트 전>

<test 후 >

6. nfsstat을 통해 현재 네트워크 파일 시스템쪽의 문제가 있는지 확인해봄
- - 상황 발생시 nfs disk io 지연 발생 가능성이 있으므로 정보를 수집한다.
- retrans ( 패킷 재전송)의 증가 여부를 확인 하면 네트워크 지연 등이 원인일수 있음
[root@ip-192-168-2-165 ~]# sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport 192.168.1.91:/ /mnt/myefs
주요 옵션 설명
nfsvers=4.1 → EFS는 NFS v4.1 또는 v4.2를 지원하며, v4.1이 기본적으로 권장됨.
hard → 네트워크 오류가 발생해도 재시도하도록 설정. soft 옵션을 사용하면 파일이 손상될 수 있음.
timeo=600 → 요청 시간 초과(timeout) 값 설정. 기본값은 600 (60초).
retrans=2 → 요청이 실패했을 때의 재전송 횟수. 기본값 2회.
rsize=1048576,wsize=1048576 → 읽기/쓰기 버퍼 크기(1MB). 성능 최적화를 위해 설정.
noresvport → 동적 포트를 사용하여 보안 그룹과 충돌을 방지.
[root@ip-192-168-2-165 ~]# nfsstat
Client rpc stats:
calls retrans authrefrsh
17 0 17
Client nfs v4:
null read write commit open
1 5% 0 0% 0 0% 0 0% 0 0%
open_conf open_noat open_dgrd close setattr
0 0% 0 0% 0 0% 0 0% 0 0%
fsinfo renew setclntid confirm lock
2 11% 0 0% 0 0% 0 0% 0 0%
lockt locku access getattr lookup
0 0% 0 0% 0 0% 1 5% 0 0%
lookup_root remove rename link symlink
1 5% 0 0% 0 0% 0 0% 0 0%
create pathconf statfs readlink readdir
0 0% 1 5% 2 11% 0 0% 0 0%
server_caps delegreturn getacl setacl fs_locations
3 17% 0 0% 0 0% 0 0% 0 0%
rel_lkowner secinfo fsid_present exchange_id create_session
0 0% 0 0% 0 0% 2 11% 1 5%
destroy_session sequence get_lease_time reclaim_comp layoutget
0 0% 1 5% 0 0% 1 5% 0 0%
getdevinfo layoutcommit layoutreturn secinfo_no test_stateid
0 0% 0 0% 0 0% 1 5% 0 0%
free_stateid getdevicelist bind_conn_to_ses destroy_clientid seek
0 0% 0 0% 0 0% 0 0% 0 0%
allocate deallocate layoutstats clone
0 0% 0 0% 0 0% 0 0%
7. 벤더 사에 확인 필요할시 노드 로그 수집 방법을 가이드 받은대로 logs_collector을 미리 스크립트 만들어두고 실행 후 메일에 첨부
- 해당 스크립트에는 이외에도 인프라 상 문제가 될만한 정보들을 수집한다.
'DevOps' 카테고리의 다른 글
| [AWS EKS] (12) EKS 스터디 4주차 ( 프로메테우스 스택 ) (0) | 2025.02.28 |
|---|---|
| [AWS EKS] (11) EKS 스터디 4주차 ( pod 로깅 ) (0) | 2025.02.27 |
| [AWS EKS] (10) EKS 스터디 4주차 ( Control-plane ) (0) | 2025.02.26 |
| [AWS EKS] (9) EKS 스터디 3주차 ( EFS Controller/ S3 CSI driver ) (0) | 2025.02.22 |
| [AWS EKS] (8) EKS 스터디 3주차 ( Storage 성능 지표 및 벤치마크 ) (0) | 2025.02.20 |



