클라우드, 가상화, 서버 , 네트워크 , 스토리지 기초에 대해서 진짜 쉽게 내 방식대로 정리해봄
엔지니어가 되고 처음에는 CPU와 메모리가 대체 무엇이지? 라는 의문이 많이 생겼었고, 구글에 검색하게 되면 항상 나오는 내용들은, 아래와 같이 무슨 말인지 이해가 안가는 이야기들 뿐이였다. 그래서 아주 쉽게 정리해봤다.
처음 선배들에게 CPU와 메모리에 대한 공부를 하면서 무엇을 물어보면 나무위키 같은 블로그 글과 알수없는 그림을 던져주곤 했다. 그리고는 "나도 사실 잘 몰라" 라고 덫붙이곤 했는데.. 나는 그런 선배가 되진 않아야겠다고 다짐했었다.
이번 글을 읽으면 당신은 아래 그림을 후배들에게 자신있게 설명해줄수 있어야 한다



1. CPU의 이해
CPU는 컴퓨터의 두뇌에 비유 합니다.
CPU는 데이터를 처리하고 명령을 실행하는 역할을 합니다. 이를 연산장치라고 합니다.
CPU가 연산을 하는데 있어서 어떤 CPU가 연산을 더 잘할까요?
아래 내용들은 CPU 성능에 초점을 맞추어 이야기를 해보려 합니다.
1-1. CPU 의 이해
- CPU의 직접회로안에 있는 코어가 많아질수록 시스템의 속도는 개선된다.
- CPU의 구성을 살펴볼때 클럭과 코어 그리고 쓰레드로 모델별로 급을 나누고 성능의 기준을 두게 된다
- 클럭 1초당 CPU 내부에서의 얼마만큼의 작업을 처리하는지를 주파수 단위로 측정
- 이전에는 멀티코어 개념이 없던 시절에는 CPU간 성능을 비교함에 있어서는 절대적인 수치는 Hz (헤르츠)만 가지고 비교
- 다중코어 또는 멀티코어의 CPU 제품군이 나타나 꼭 Hz(주파수)가 높지않아도 코어가 많은지 유무로 급을 나누고있어 헤르츠도 물론 중요하지만 헤르츠보다 코어가 더 중요하게 따져보게되는 사항중 하나로 위치해 있다
- 그 이유는 클럭 rate는 더 이상 발전 할 수 없을정도로 발전 되었다.
- 코어 클럭이 1개의 코어가 얼마만큼의 작업을 처리하는지의 단위 였으니까 당연히 코어가 많으면 많을수록 더 많은 작업을 할수 있다.
- vCPU 와 코어의 개념에 대해서 설명 : vCPU는 코어에 하이퍼스레딩의 기술을 적용하여 몇배로 보이게 만든 것이고. 코어는 실제 물리적 코어를 뜻한다. 물리적인 코어에 가상화 기술을 더하여 ( 하이퍼스레딩 말고도 효율적인 리소스 분배 기술들이 많다. ) 논리적으로 더 많은 가상자원이 있는것처럼 속이는 것이다.
- AWS에서 EC2를 배포할때 다음과 같은 화면을 볼수 있다. (vCPU: 코어 x 코어당 스레드)

- 쓰레드 : 하이퍼 쓰레딩, 멀티 쓰레딩 같은 기술이 발달되면서 1개의 코어를 좀 더 효율적으로 사용할수 있게 되었다.
- 코어는 한번에 한가지 일밖에 못한다. 사실 우리 컴퓨터에서 여러개의 프로그램이 켜져 있을때 동시 작업되는것 처럼 보이지만 엄청 빠르게 돌아가면서 일을 하는것인데 그 처리속도가 어마어마하게 빨라서 그렇게 보이는것이다.
- 1980~ 2004년까지 싱글코어로도 충분했다. 심지어 빌게이츠도 멀티코어가 도래할것이라 상상도 하지 못했다. MS의 대부분 어플리케이션이 그렇게 개발 되어 있었던것.. 특히 OS.. 그래서 인텔은 MS 의 윈도우 OS를 벗어나려는 노력을 한적도 있다. 물론 그러지 못했지만..
- 하지만, CPU의 성능은 한계가 있었다. ( 열을 잡지 못함 .. 쿨러가 아무리 좋아져도.. )
- 2004년도 intel에서 싱글코어 손절 발표 함. 2005년에 스레드 기술 발표 (하이퍼 스레딩(HT)= 갓 인텔 ) ,, ( AMD의 SMT ) -> 쓰레드는 코어를 여러개로 쪼개서 작업 단위로 삼는다. 그래서 논리적 코어라고도 불린다.
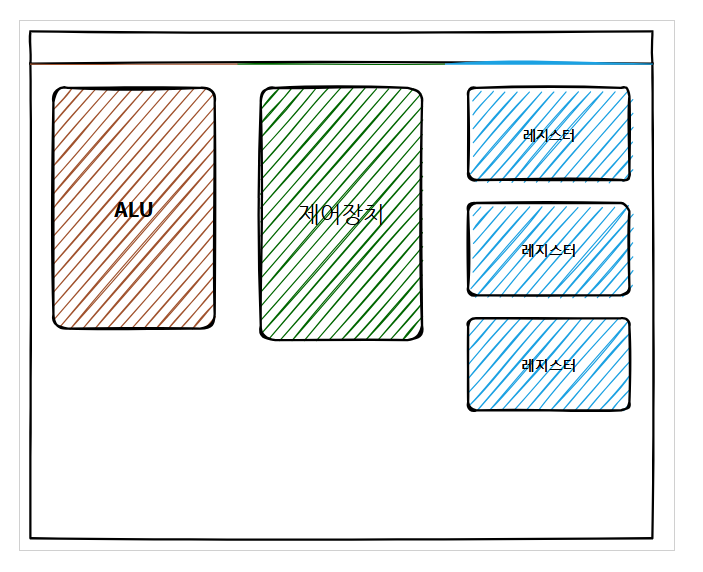
1-2. CPU 구성요소
- 제어장치 - 제어 신호(control signal)를 통해서 명령어를 해석, 조작을 지시하는 장치
- 레지스터 - CPU가 요청을 처리하는 데 필요한 데이터를 일시적으로 저장하는 기억장치
- ALU - 계산기로 덧셈, 뺄셈 같은 두 숫자의 산술연산과 배타적 논리합, 논리곱, 논리합 같은 논리연산을 계산하는 디지털 회로
1-3. CPU 성능
CPU 성능은 코어수와 1초당 작업 처리 주파수 단위로 측정
- CORE CPU에서 코어(core)는 연산 작업을 수행하는 핵심적인 부분이며, CPU의 성능을 판단하는 기준 중 하나가 바로 코어의 수입니다
- 코어 / 쓰레드
- 코어는 두뇌라고 따지자면 쓰레드는 손과 다리의 역할이 되겠다
- 인텔의 경우 하이퍼 쓰레딩이라는 기술을 통해 코어를 반으로 또 분리하는 기술
- 쓰레드로 논리적 코어로 쪼개면 처리해주는 속도가 향상 즉 성능 개선 가능
- SOCKET CPU 소켓은 마이크로 프로세서와 마더 보드 사이의 연결점 입니다. CPU 소켓은 정확한 회로 칩 삽입을 보장하기 위해 마더 보드의 CPU에만 사용되는 고유한 껍데기입니다. CPU 슬롯이라고 부르는데 ( CPU slot ), 그 명칭에 알수있듯이 그안에 CPU 칩이 들어가서 마더보드 안에 존재 하는 형태.
- 오버클럭 CPU에 강제로 전압을 더 공급하여 일반적으로 정해져있는 헤르츠를 보다 더 높여 성능을 올리는 것을 오버클럭이라고 한다
- 전압을 강제로 더 공급하기 때문에 갑작스런 시스템다운이나 문제를 만들어내는 경우
- 발열이 올라간 만큼 발열 해소를 위해 CPU에 장착하는 CPU쿨러 필요
1-4. CPU 스케쥴링

✔️ OS가 cpu를 사용하려고 하는 프로세스들 사이의 우선순위를 관리하는 작업
✔️ 자원을 어떤 프로세스에 얼마나 할당하는지 정책을 만드는 것
- 프로세스들에게 자원을 최대한 공평하게 배분하며 처리율과 CPU 이용률을 증가시키고
- 오버헤드, 응답시간(Response time / Turnaround time), 대기시간을 최소화하기 위한 기법
CPU 스케쥴링에 대해서 알기위해 리눅스의 CFS 스케쥴러를 대표적으로 알아두는게 좋다
Completely Fair Scheduler 라는 이름에서 유추 가능한것 처럼
리눅스는 CPU를 공평하게 분배하는데 초점을 둔다. 즉 모든 프로세스가 공평하게 자원을 할당 받을수 있도록
오랫동안 대기한 프로세스에 더 높은 우선 순위가 부여될 확률이 높은 알고리즘이다.
그러기 위해서는 Timer, Time Slice, Queue, Bit Map 등에 대해서 찾아보면서 학습해보는것을 추천드립니다.
1-5. CPU 하이퍼스레딩
✔️ 하이퍼스레딩은 동시 멀티스레딩을 구현한 기술이다. HT 라고 인텔은 부르고, SMT 라고 AMD는 부른다.
✔️ 물리상 실행 장치 한 개에 가상 실행 장치 두 개(논리적 코어)를 할당해 성능을 높이려는 기술이다. 요즘은 인텔에서 나오는 pc들도 다 하이퍼스레딩 기술을 포함하고 있다.
✔️ 사실 하이퍼스레딩은 정말 중요한 기능이다. 하이퍼스레딩 기술을 사용하면 단일 물리적 프로세서 코어를 논리 프로세서가 두 개인 것처럼 성능을 향상 시킬 수 있다. 아니 그런데 성능을 향상 시킬수 있으면 마냥 좋은것 아니야? 당연히 아니지. 마냥 좋은것은 세상에 없다.
Memory IO는 ..?CPU의 성능이 단일코어로 18개월에 2배씩 증가 한다는 무어의 법칙(인텔 창시자)과는 다르게
발열을 잡지 못해서 하이퍼스레딩 기능이 핵심 아키텍처로 자리잡았다. 하지만 CPU의 성능은 계속적으로
드라마틱한 성장을 하지만.. 메모리와 이어주는 Memory Bus의 성능은 10년간 3.25배 정도 뿐이 증가하지 못했다. 그로 인해 CPU 이용률에는 Memory의 느린 처리 속도를 기다려주는 IO wait라는 시간이 포함되어 있는
웃기지만 슬픈 상황이다.
이러한 상황에 이제 멀티 스레딩도 MAX 카운트 스레드 or 소켓의 시대가 올것이다.
즉, 반대로 말하면 Optimizing 과 Cost에 대한 중요성이 클라우드 뿐만 아니라 PC를 사용하는 모든 환경에서
중요해 질 것이라는 이야기다.
그로인해 커널에 대한 성능개선과 k8s로 따지면 현재 Cilium과 같은 iptables를 탈피하려는 현재 지속적으로
발생 하고 있는 레거시의 문제점들을 개선하려는 움직임이 많다. 따라서 개발자, 시스템 운영자 모두 근 10년 안에 커널에 기본적인 코드 정도는 작성할수 있는 수준을 요구하게 될 것이다.
2. Memory의 이해
1-1. Memory 구성요소
메모리는 왜 중요한가?
메모리는 리눅스 시스템에서 프로세스가 연산할수 있는 공간을 제공해주는 리소스입니다.
메모리가 부족하면 연산이 불가능 해지고, 이후 메모리를 필요로 하는 프로세스들은 죽거나, 성능 저하를 초래합니다.
그러므로, 메모리를 이해하는것이 매우 기본이며 중요하다고 볼수 있다.
메모리는 무엇일까?
사용자가 자유롭게 내용을 읽고 쓰고 지울 수 있는 기억장치. 컴퓨터가 켜지는 순간부터 CPU는 연산을 하고 동작에 필요한 모든 내용이 전원이 유지되는 내내 이 기억장치에 저장된다. '주기억장치'로 분류되며 보통 램이 많으면 한번에 많은 일을 할 수 있기에 '책상'에 비유되곤 한다
PC 시스템에서 램(RAM)이 존재하는 이유를 단적으로 말하자면 CPU의 속도에 비해서 HDD의 속도가 너무 느리기 때문입니다.
- 램은 하드디스크로부터 일정량의 데이터를 복사해 임시 저장한 후, 이를 필요로 할때마다 CPU에 빠르게 전달하는 역할을 합니다
- 용량: 기가바이트(GB) 단위로 측정됩니다. 용량이 높을수록 응용 프로그램이 더많은 데이터를 저장할 수 있습니다.
- 용량이 높을수록 더 많은 응용 프로그램을 동시에 실행할 수 있으며, 더 많은 양의 임시 데이터를 저장할 수 있습니다.
- 속도: 헤르츠 ( Hz ) 단위로 측정됩니다.
- 속도 등급이 높을수록 읽기 및 쓰기 요청에 관한 응답이 빨라져 성능이 향상됩니다.
- 용량: 기가바이트(GB) 단위로 측정됩니다. 용량이 높을수록 응용 프로그램이 더많은 데이터를 저장할 수 있습니다.
1-2. Memory 이용률
- CPU의 코어 기반 계산과 달리 GB 와 같은 정량적 기준을 가지고 판단한다.
- 디스크의 계산 단위와 동일한것을 보아 저장 장치라는 것을 알수 있다.
- 사용하고 있는 메모리양 / 할당 받은 가상머신의 메모리 양으로 이용률을 계산한다.
1-3. Memory 종류

✔️ 메모리는 작고 비쌀수록 빠르다. SRAM에 RAM이라는 단어를 보고 메인 메모리랑 헷갈리면 안됨 /// 아무튼 아직 당신이 컨테이너 레벨에서 성능 관련한 업무까지 (벤치마킹 수준) 을 해야하는 상황이 아니라면 간단하게 읽고 넘어가도 된다. 아래 블로그 참고~
✔️ 메모리의 종류를 이런걸 다 암기하라는 이야기가 아니다. 다만, NUMA 아키텍처나 하이퍼스레딩을 이해하려면 이해는 필요하다. 그리고 어느정도 알면, 주식 할때 삼성전자에 안물릴수 있다. ㅋㅋㅋ (난 몰라서 평단 8만원에 물림)
물론, 주식 이야기는 농담이고, L1 캐시나 L1~L3 캐시를 많이 사용 하는 어플리케이션 경우에 CPU set 과 같은 고정 CPU 스케쥴링 방식을 써서 효율과 성능을 개선하는 경우들이 있는데 극단적으로 SK 하이닉스 같은 Big data 플랫폼과 같은 경우에나 그러하다. 그러한 환경에서 벤치마킹을 해야하는 경우에 다시 들여다 봐도 될거 같다.
[root@ip-172-31-41-239 bin]# lscpu
...<SNIP>...
Caches (sum of all):
L1d: 64 KiB (2 instances)
L1i: 64 KiB (2 instances)
L2: 512 KiB (2 instances)
L3: 25 MiB (1 instance)
...<SNIP>...
[root@ip-172-31-41-239 bin]# lscpu -p
# CPU,Core,Socket,Node,,L1d,L1i,L2,L3
0,0,0,0,,0,0,0,0
1,1,0,0,,1,1,1,0
2,0,0,0,,0,0,0,0
3,1,0,0,,1,1,1,0
1-4. 리눅스의 메모리 관리
free 명령어 .. 알고 쓰시나요? ( 토스 이재성님의 글을 읽고 정리해봤다 )
[root@mzctest-m-master1 ~]# free -h
total used free shared buff/cache available
Mem: 15Gi 3.5Gi 420Mi 83Mi 11Gi 11Gi
Swap: 0B 0B 0B
free 명령어는 다음과 같이 이루어져있다.
- total 리눅스 전체 메모리 크기
- used 사용중인 메모리
- shared 공유 메모리는 tmpfs에서 사용되는 메모리이다.
- buffer, cache 메모리 : 커널이 성능 향상을 위해 캐시 영역으로 사용 하는 메모리 크기이다.
- swap 메모리
버퍼와 캐시 ?
먼저, buffer / cache를 사용하는 이유를 알아야 한다.
블록 디바이스라고 불리는 하드 디스크 등의 저장 장치는 아주 거대한 저장 장치이지만, 속도가 매우 느리다.
매번 I/0 요청마다 디스크에 접근 하여 파일을 읽고 쓰게 된다면, 상당한 시간을 기다려야 하며, 시스템에도 부하가 생김
이러한 문제를 캐싱으로 해결하는데, 커널은 디스크와 CPU의 속도 차이를 해결 하기 위해 캐시 영역에 한번 읽은 파일을
저장한 뒤, 다시 해당 파일을 읽으려 할때 상대적으로 매우 빠른 메모리 영역을 활용하여 속도 차이를 극복한다.
즉, 커널이 전체적인 성능 향상을 위하여 사용하는 메모리의 일부 영역을 buffer,cache라 부른다.
리눅스 Centos 7 버전 이하에서는 buffer와 cache를 분리해서 명시했었다.
그렇다면 buffer와 cache는 각각 어떤 의미일까?
여기서의 cache는 Page cache + slabs을 의미한다.
✔️ 페이지 캐시
Page cache는 리눅스 커널이 I/O 성능을 향상 하기 위하여 사용하는 메모리 영역이다.
커널은 느린 디스크 접근의 단점을 보완하기 위하여 한번 읽은 파일의 내용을 커널 메모리의 일부분인 Page Cache에 저장한다.
이후 재접근이 일어나게 될 경우 디스크의 내용을 전달하는것이 아닌 메모리의 Page Cache 영역에 저장된 내용을 전달함으로써 빠른 접근을 가능하게한다. 이를 Page 단위로 관리하기 때문에, Page Cache라고 부른다.
✔️ 버퍼 캐시
Page Cache와 동일하게 리눅스 커널이 I/O 성능을 향상 하기 위해 사용하는 메모리 영역이다.
Page Cache는 파일의 내용을저자d했다면 Buffer cache는 파일의 내용이 아닌 UFS 기준으로 Super block과 inode block에 해당하는 메타 데이터를 저장한다. 디렉토리를 읽고자 하는 경우에는 디렉토리에 포함된 파일들의 inode block들을 버퍼 캐시에 저장한다. 이후 접근 시 buffer cache에 존재 하는 값을 가져다 보여준다. 실제로 ls 명령어를 입력하면 free 명령어의 buffers 결과가 달라짐을 확인 할수있다.
✔️ Slab 영역
커널 역시 프로세스 이므로 메모리가 필요하다. 즉 slab 영역이란 디렉토리 구조를 캐시하는 dentry cache와 파일의 정보를 저장하고 있는 inode cache 등 커널이 사용하는 메모리영역을 말한다.
가상메모리
이 그림을 보면 CPU가 일을 할때 메모리를 어떻게 사용하는지에 대해 이해할수 있습니다.
가상 메모리는 메모리의 크기를 속이는 기술이다. 물리 메모리 공간과 스왑 공간을 합쳐서 만든 가상메모리 공간을 실제 물리 메모리인것 처럼 속이는 기술입니다. 물리주소와 논리주소를 구분하는 이유는 뭘까요? CPU는 논리주소만 읽을수 있기 때문입니다.
CPU는 현재 활동중인 프로세스의 내부 주소만 알면되지, 어떤 프로세스인지 알필요도 없고 알수도 없습니다.
✔️ MMU?
그렇다면 어떤 프로세스인지도 모르는데 정보를 읽는것이 어떻게 가능할까요? MMU 덕분입니다. 즉 소프트웨어적으로는 물리주소를 찾도록 도와줄 방법이 없습니다. 하드웨어적인 도움이 필요하겠죠. MMU는 Memory Management Unit 이라는 하드웨어입니다.
MMU는 base register + limit register을 통해 논리주소를 물리주소로 변경해주는 작업을 합니다.
✔️ TLB?
TLB는 최근 사용한 논리주소를 캐시에 저장해두고 꺼내주는 하드웨어 장치입니다. CPU의 캐시와 유사한 고속 메모리입니다.
결론적으로, 요약해서 정리하자면
1. CPU는 가상 주소로 메모리를 요청할때 먼저 TLB를 조회합니다.
2. TLB에 정보가 있다면, 즉시 TLB에 저장된 물리주소를 가져와서 접근할수 있습니다.
3. TLB에 정보가 없다면, MMU가 페이지 테이블을 참조 해야합니다. 참조하여 가상주소를 물리주소로 변환시킵니다.
4. 이때, 페이지 테이블에도 변환 정보가 없다면, 페이지 폴트가 발생합니다.
5. 운영체제는 디스크에 있는 데이터를 물리 메모리로 가져와 페이지 테이블과 TLB를 업데이트 한 후 다시 요청을 처리
이러한 페이지 폴트 과정이 디스크 I/O가 많이 발생하며 시간이 오래 걸리므로 CPU 성능에 영향을 미칩니다.
사실상, 여기까지 이야기들은
내가 진정 하고싶은 이야기의 빌드업들이였다.
결론적으로 이야기 하고 싶은 부분은, CPU 사용률 중에 memory io wait 부분에 대한 이해가 없다면
실제로 내 Linux의 성능저하가 어디서 오는지 알수 있는 방법이 없다.
최근 커널에 대한 개발 수준이 대중화 되면서 그동안 블랙박스 영역이던 커널에 대한 Observablity 즉 가시성이
확보되고 있다.
그로인해 엔지니어들도 그에 걸맞는 수준을 확보해야 하는 상황이고
그에 대한 준비가 필요하다.
관련해서 https://www.brendangregg.com/linuxperf.html 중요한 자료들이 많아서 참고하면서 공부 해보세요~
Linux Performance
Linux Performance This page links to various Linux performance material I've created, including the tools maps on the right. These use a large font size to suit slide decks. You can also print them out for your office wall. They show: Linux observability t
www.brendangregg.com
브랜든 그랙이라는 사람인데 Linux Performance에 대해 굉장히 깊게 파고든 사람입니다.
《Systems Performance: Enterprise and the Cloud 2/E》 이 책을 쓴 사람이고
이사람은 넷플릭스의 선임 성능 엔지니어인데, BPF(eBPF)의 주요 기여자로 BPF 개발 초기에 참여해서
주요 BPF 프론트엔드 개발과 관리를 도왔고, BPF를 관측가능성 용도로 사용하는 방식을 개척했으며, 수많은 BPF 기반 성능 분석 도구들을 만들었습니다.
특히 2021년 7월 5일 유닉스 유저 그룹에서 한 발표를 참고 해서 공부 하길 바랍니다.
USENIX 협회는 고급 컴퓨팅 시스템스 협회(Advanced Computing Systems Association)이다. 1975년 유닉스 유저스 그룹(Unix Users Group)이라는 이름으로 설립
https://www.brendangregg.com/blog/2021-07-05/computing-performance-on-the-horizon.html
'잡다구리 > 서버' 카테고리의 다른 글
| 클라우드란 무엇인가요? (0) | 2023.08.24 |
|---|---|
| [Linux] 리눅스 커널이란? (1) | 2022.02.07 |
| [Linux] systemd 와 service의 차이점 (0) | 2021.08.04 |
| [Linux] 환경변수 설정 (0) | 2021.06.15 |
| [Linux] Apache 소스설치 (0) | 2021.06.14 |



